Amazon Bedrockに新登場した「Knowledge base」を試してみた(Pinecone利用編)
2023年の「AWS Community Builders Advent Calendar」の記事では、Amazon BedrockにRAG(検索拡張生成)を行うためのナレッジベース機能が登場したことが紹介されています。記事では、ナレッジベースを利用するための準備や設定方法、テストの方法などが詳しく説明されています。Pineconeを使用した準備や設定方法、データソースの同期など、具体的な手順も紹介されています。また、テストを通じて回答結果を確認し、データソースの参照もできることが強調されています。RAGの実装は、LangChainなどと比較してノーコードで行えることが特徴的であり、Agent側は独自実装にすることも可能です。
この記事は、「AWS Community Builders Advent Calendar 2023」4日目の記事です。
Amazon BedrockにRAG(検索拡張生成)を行うためのナレッジベース機能が登場しました。RAGはかなり興味のある分野ですので、早速触ってみました。
目次
Knowledge baseを使うための下準備: Pinecone編
Knowledge baseを利用するには、Vector DBが必要です。AWSの場合はOpensearch Serviceを使うことになりますが、今回は別件で試し中だったPineconeを利用しました。
AWSの外にあるリソースを利用するため、接続情報をAWSに保存する必要があります。Knowledge baseで利用するには、AWS Secrets Managerを利用しましょう。
[キー/値のペア]で利用するキー名は、公式のブログで紹介されている設定をそのまま使っています。
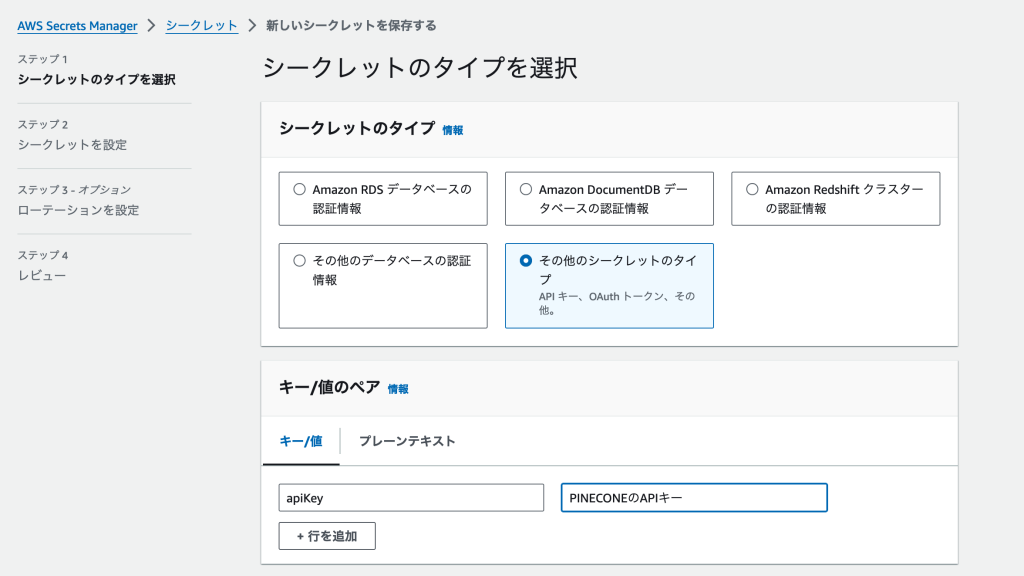
シークレットの名前は、[Bedrock用のPineconeリソース情報]であることがわかればなんでも良いと思います。
作成しました。[シークレットのARN]を後で使いますので、別タブで開いておくか、ARNをコピーしておきましょう。

Bedrock Knowledge baseを作ってみた
準備ができたので、早速作ってみましょう。[Create knowledge base]ボタンから作成を開始します。
いつものウィザードが立ち上がってきます。まずはリソースの名前と説明、そして利用するIAMロールの設定を行います。IAMロールは新しく作る方法をとりました。
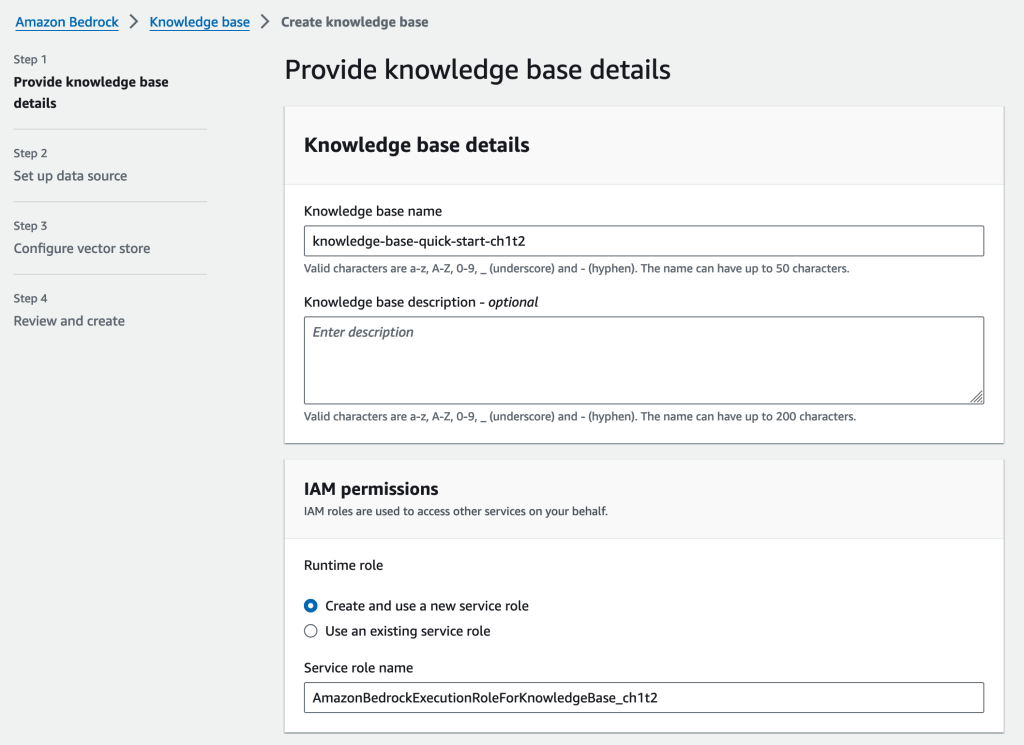
データソースにするS3バケットを指定します。[S3 URI]はs3://BUCKET_NAMEで登録しましょう。
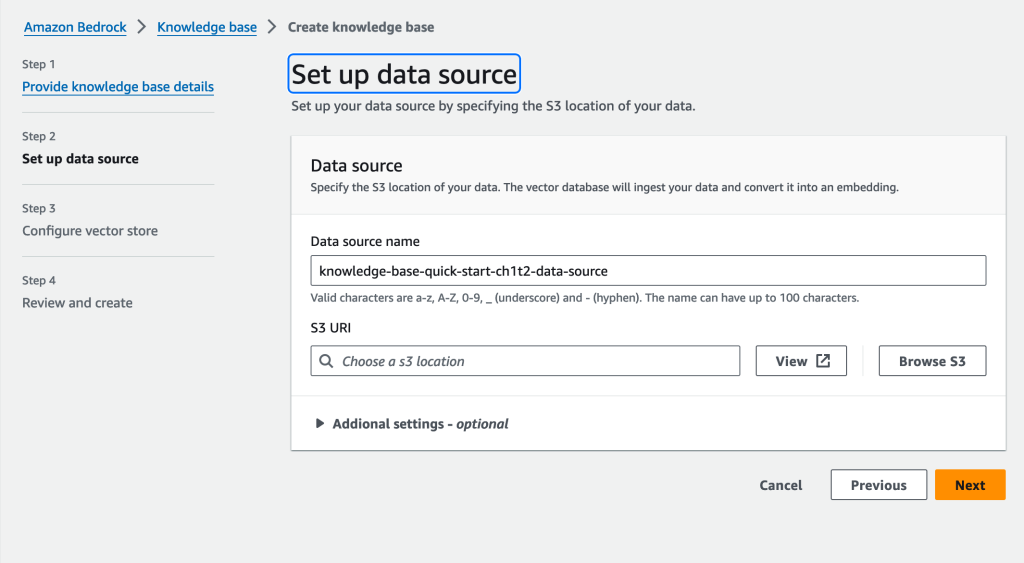
続いてEmbedding時に利用するモデルと、Embeddingされたベクトルデータを保存するDBを指定します。
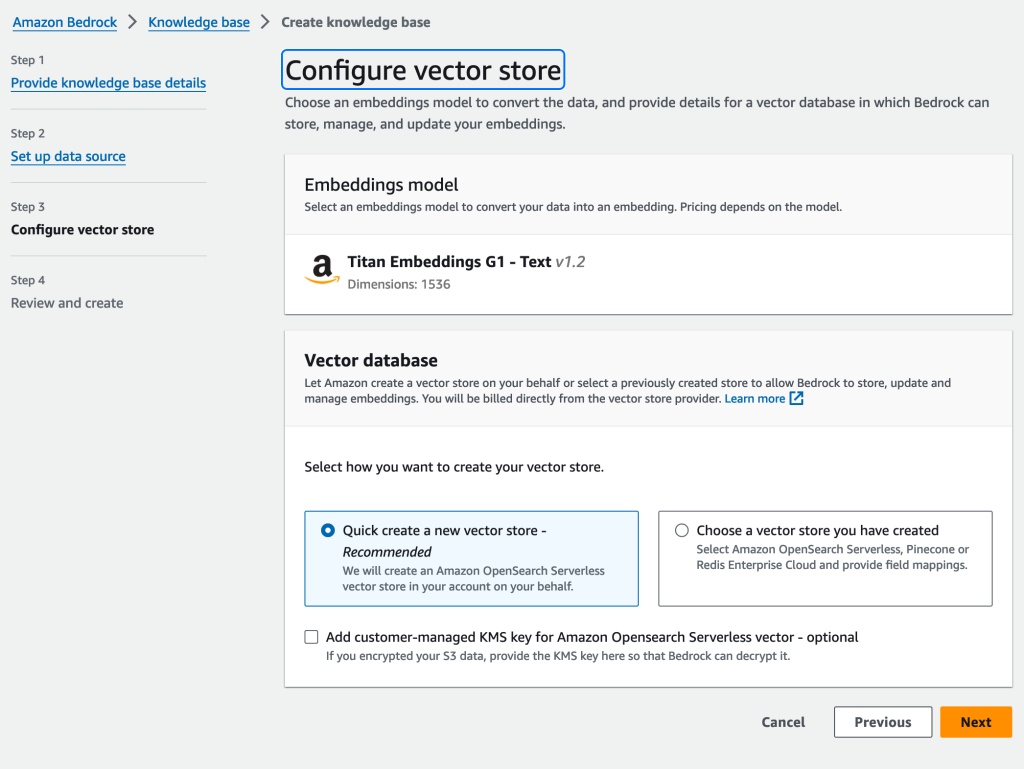
Pineconeを使う場合は、[Choose a vector store you have created]を選ぶ
今回はPineconeで作成済みのDBを利用します。そのため、[Choose a vector store you have created]を選びました。するとOpensearch Serverless / Pinecone / Redis Enterprise Cloudの3選択肢が出てきますので、[Pinecone]を選びましょう。
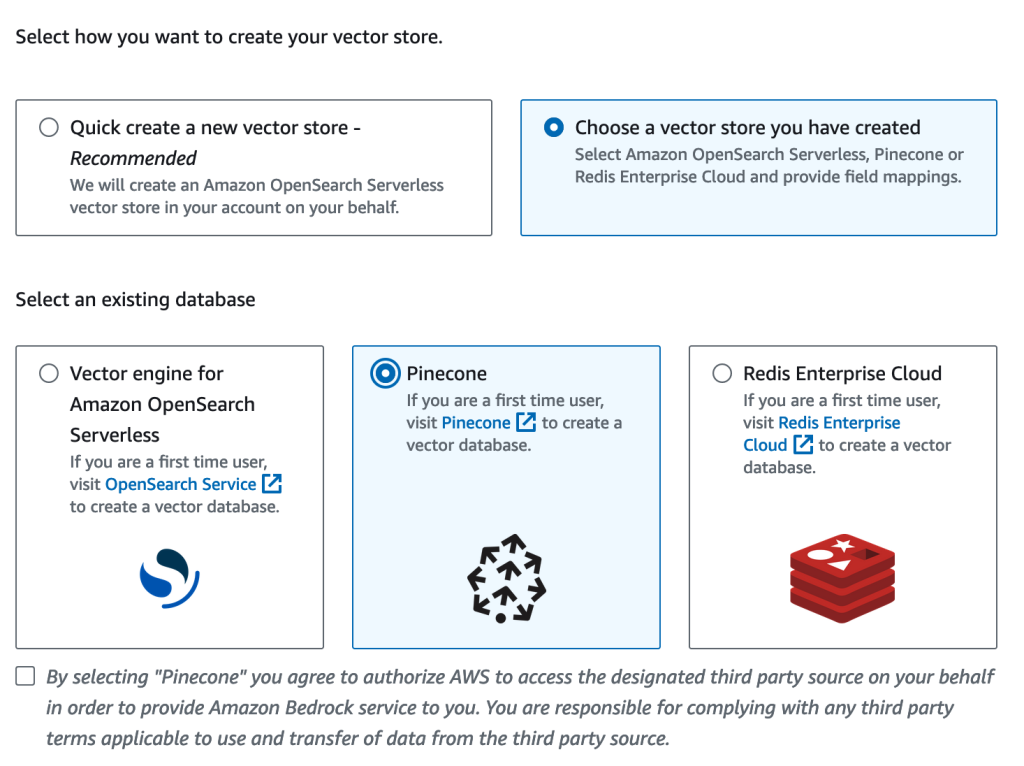
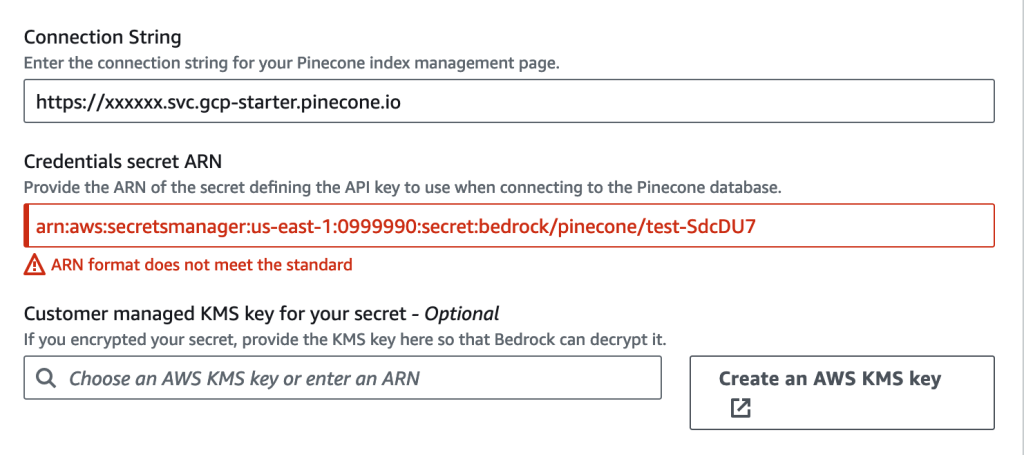
接続設定では以下の2項目が必要です。
- Connection String: PineconeのDB URL
- Credentials secret ARN: 事前準備で作成したSecrets ManagerのARN
「PineconeのDB URL」は、Pineconeのダッシュボードから取得できます。
入力が終わると、このような感じになります。Secret ARNにダミーの値を入れているため、スクリーンショットではエラーになっていますが、正しいARNを入れていればOKです。
マッピング設定を行う
この辺りから知識不足による手探りが始まります。[Metadata field mapping]はひとまずPinecone側のブログを参考に、同じ値を入れるようにしました。

レビューとKnowledge base作成
最後に設定内容をレビューした後、作成を開始します。
数分足らずで立ち上がってきました。
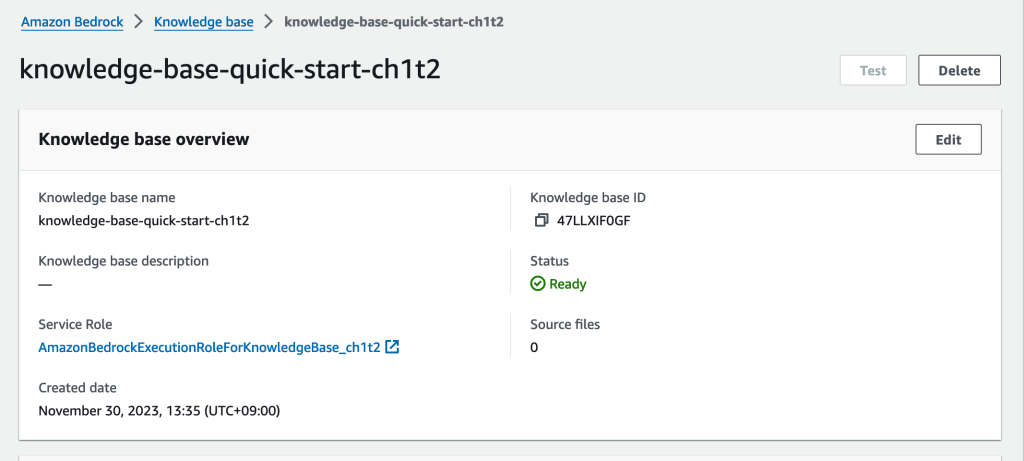
データを更新した場合は、syncが必要な様子
knowledge baseが参照するデータはS3に配置する必要があります。ただし配置したデータはEmbedding処理される必要があるためか、[Sync]が必要でした。
ページをスクロールすると、[Data source]セクションがあります。そこでデータを更新したものを選択し、[Sync]しましょう。
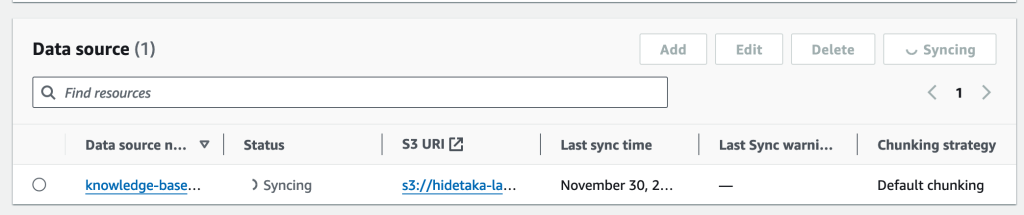
テストデータとして、StripeのOpenAPI SpecificationをS3バケットにアップロードしてみました。Syncしてみたところ、PineconeのIndexからもデータを見ることができました。

「S3に元データ」そして「Knowledge baseの検索処理自体は、Vector DB」という使い分けになる様子ですね。
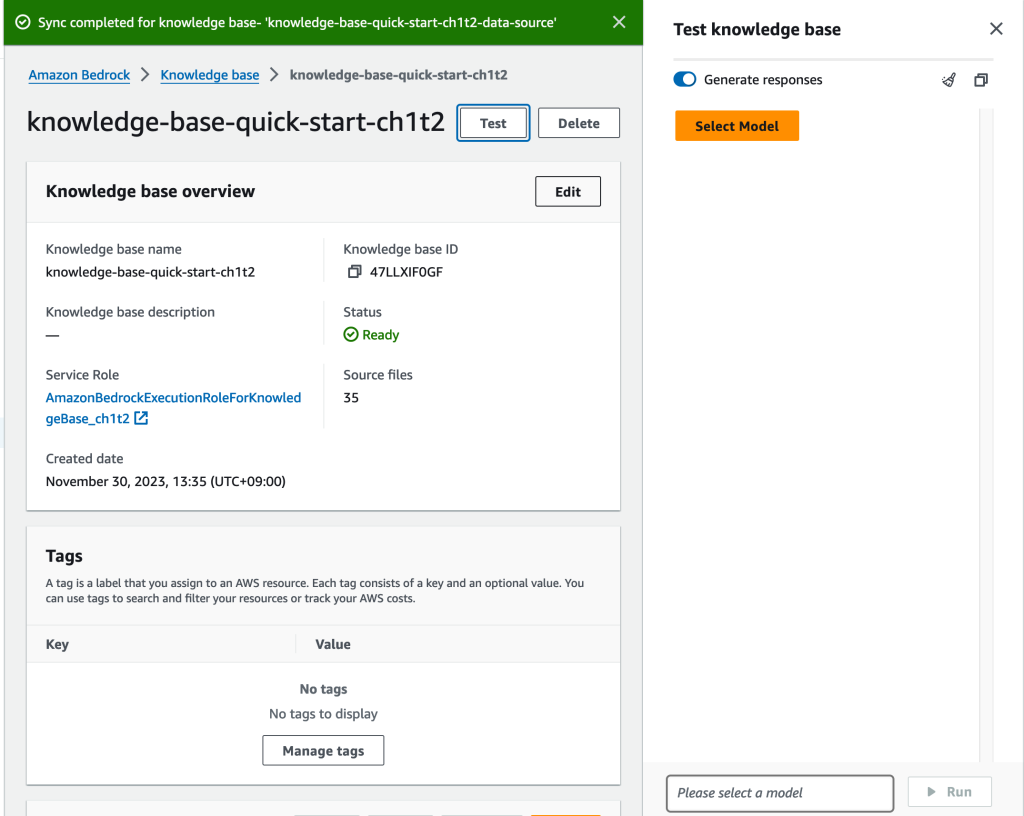
作成したKnowledgeベースをテストする
[Data source]のSyncが終わっている状態ならば、Knowledge baseのテストがマネージメントコンソールからできます。
テストにつかうモデルを選びましょう。
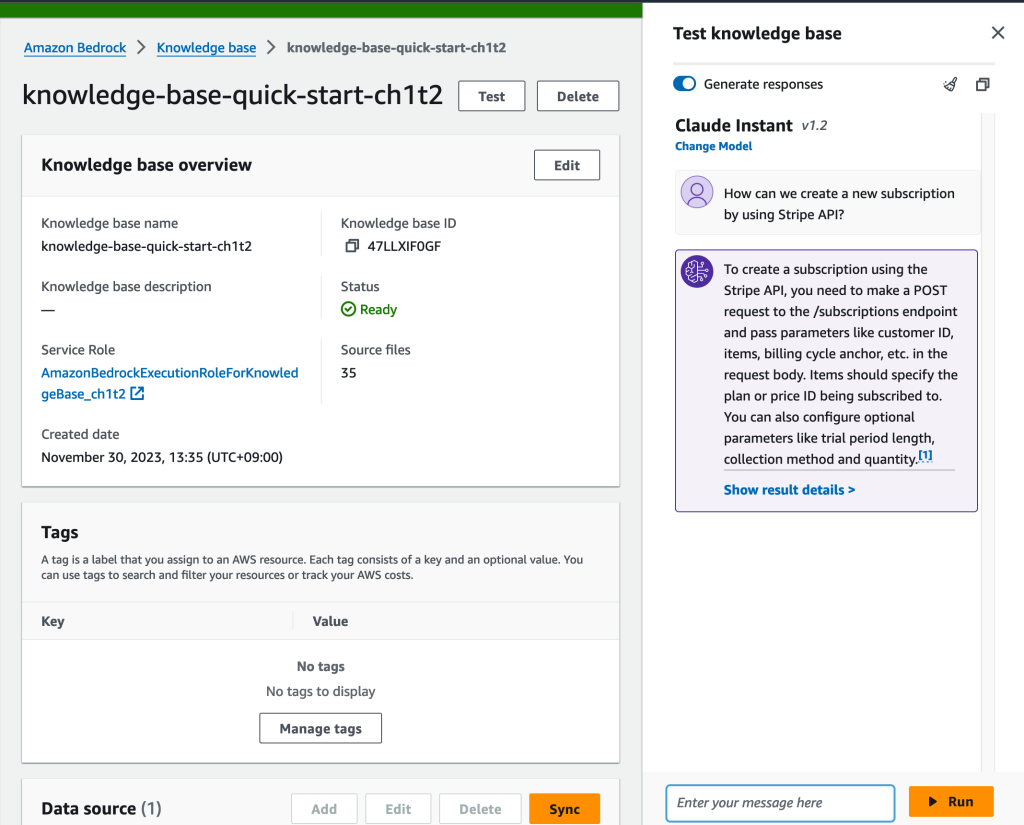
モデルを選択すると、テストが行えるようになります。Stripeのドキュメントを投入しているので、How can we create a new subscription by using Stripe API?と質問してみました。すると「/subscriptionsエンドポイントにPOSTを投げろ」や「price IDやCustomer IDなどが必要」など、Stripe APIの仕様に基づいた返事が返ってきます。
「Claudeならば日本語でもやりとりできるのでは?」と思い、日本語でも質問してみました。
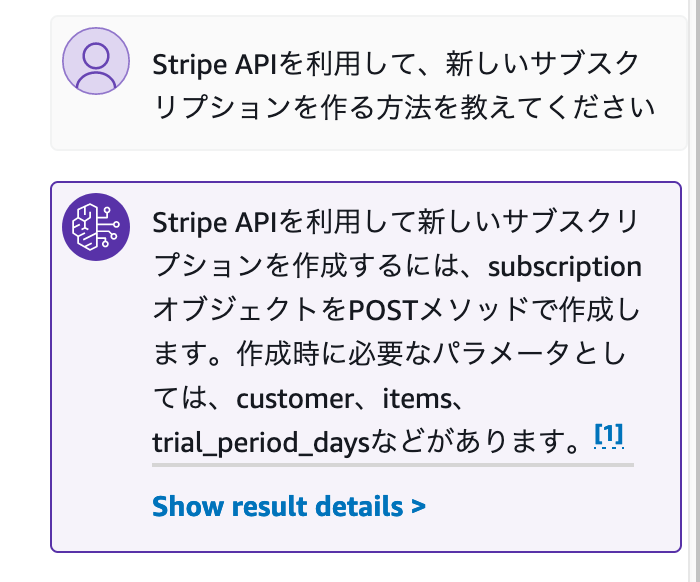
英文に比べると、少しそっけない気もしますが、回答自体は問題なさそうです。
参照したデータを確認できる
Knowledge baseが面白いなと思った点の1つが、「このデータを参照して回答文を作ったよ」を提示してくれることです。
テストでの返答文についている[Show result details]をクリックすると、参照したデータソースが表示されます。
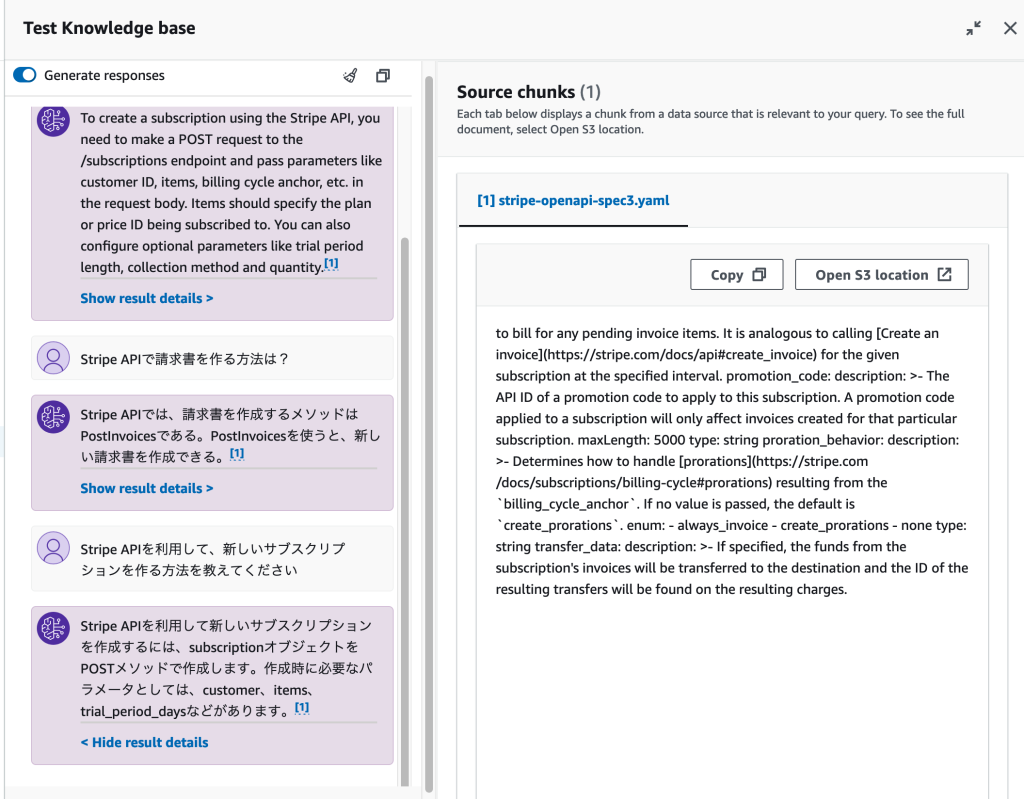
「投入したデータを意図した通りに解釈しているか」や「なぜ意図しない返答をしているのか?何をみてそう判断したのか?」を調べるのに使えそうです。
触ってみての感想
LangChainでRAGを作る試行錯誤をやっていたからか、マネージメントコンソールの操作だけでほぼほぼ出来上がってきたのはなかなか衝撃です。「RAGのembedding / Index部分がノーコードでできるようになった」と捉えるのが、LangChainなどと比較する際の表現に近しいかもしれません。
また、Embeddingデータ自体はPineconeやOpensearchに投入されるため、「S3に置いたファイルを定期的にEmbeddingする仕組み」だけにKnowledge baseを使って、Agent側はLangChainなどを使った独自実装にするみたいなことも、理論上はできそうかなと思いました。

ブックマークや限定記事(予定)など
WP Kyotoサポーター募集中
WordPressやフロントエンドアプリのホスティング、Algolia・AWSなどのサービス利用料を支援する「WP Kyotoサポーター」を募集しています。
月額または年額の有料プランを契約すると、ブックマーク機能などのサポーター限定機能がご利用いただけます。
14日間のトライアルも用意しておりますので、「このサイトよく見るな」という方はぜひご検討ください。