LangChainでSupabaseのHybrid searchを試してみた
SupabaseとOpenSearchなどでは、ベクトル検索と全文検索の両方を組み合わせたHybrid Searchが可能です。LangChain経由でSupabaseのHybrid Searchを試す方法や、ベクトル検索用のテーブル生成や関数作成の手順が説明されています。また、実際に検索を行う際のコード例も示されています。Hybrid Searchでは、Retrieverとしての役割を担うようです。関連するドキュメントやサンプルコードも紹介されています。
目次
SupabaseやOpensearchなどでは、ベクトルを利用した検索と全文検索の両方を利用したHybrid searchが利用できます。今回はLangChain経由でSupabaseのHybrid Searchをためしてみました。
SupabaseでSQLを実行する
DocsのSQLを実行しましょう。ベクトル検索に対応したテーブルの生成とベクトル検索・全文検索用のPostgre Functionを作成する様子です。
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store your documents
create table documents (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);
-- Create a function to similarity search for documents
create function match_documents (
query_embedding vector(1536),
match_count int DEFAULT null,
filter jsonb DEFAULT '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$;
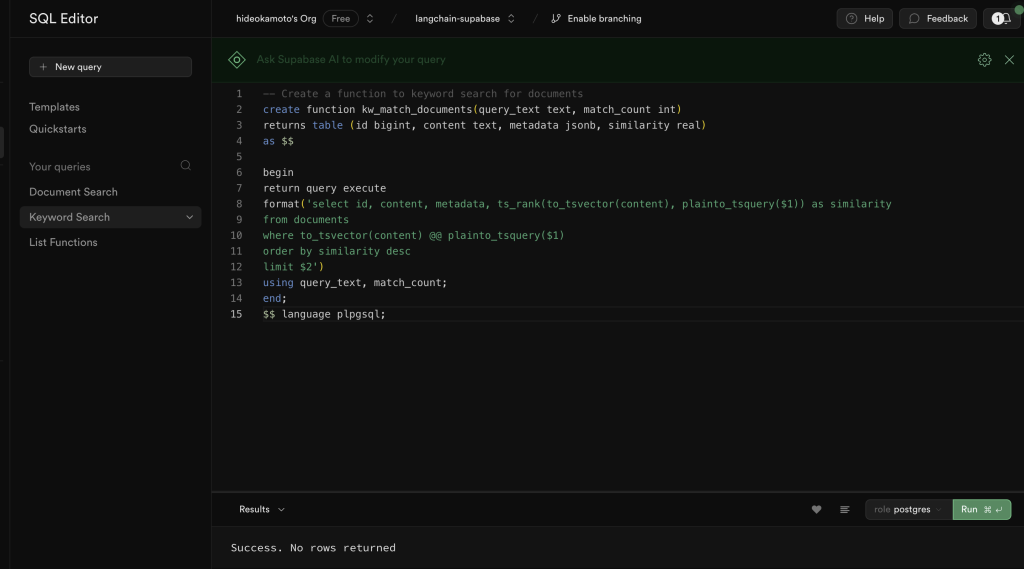
-- Create a function to keyword search for documents
create function kw_match_documents(query_text text, match_count int)
returns table (id bigint, content text, metadata jsonb, similarity real)
as $
begin
return query execute
format('select id, content, metadata, ts_rank(to_tsvector(content), plainto_tsquery($1)) as similarity
from documents
where to_tsvector(content) @@ plainto_tsquery($1)
order by similarity desc
limit $2')
using query_text, match_count;
end;
$ language plpgsql;
kw_match_documents以外をすでに作成している場合(HybridじゃないSearch / RAGをやっていた時など)は、これだけで良さそうです。
-- Create a function to keyword search for documents
create function kw_match_documents(query_text text, match_count int)
returns table (id bigint, content text, metadata jsonb, similarity real)
as $
begin
return query execute
format('select id, content, metadata, ts_rank(to_tsvector(content), plainto_tsquery($1)) as similarity
from documents
where to_tsvector(content) @@ plainto_tsquery($1)
order by similarity desc
limit $2')
using query_text, match_count;
end;
$ language plpgsql;SQL Editorで実行するのがお手軽です。
LangChain & OpenAIでHybrid Searchを実装する
あとはサンプルコードをそのまま動かすだけです。今回は別の記事などでOpenAI APIからEmbeddingしたデータをすでに投入されている想定で、検索部分だけ実装します。LangChain内部の扱いとしては、Hybrid SearchはRetrieverになる様子ですね。
const privateKey = c.env.SUPABASE_PRIVATE_KEY;
const url = c.env.SUPABASE_URL;
const client = createClient(url, privateKey);
const embeddings =new OpenAIEmbeddings({
openAIApiKey: c.env.OPENAI_API_KEY
});
const retriever = new SupabaseHybridSearch(embeddings, {
client,
// Below are the defaults, expecting that you set up your supabase table and functions according to the guide above. Please change if necessary.
similarityK: 2,
keywordK: 2,
tableName: "documents",
similarityQueryName: "match_documents",
keywordQueryName: "kw_match_documents",
});
const results = await retriever.getRelevantDocuments("hello bye");
実行すると、similarityKやkeywordKの件数だけデータが取得できます。
[
{
"pageContent": "Bye bye",
"metadata": {
"id": 1
}
},
{
"pageContent": "Hello world",
"metadata": {
"id": 2
}
}
]長めのコンテンツを投入してみる
試しにもう少し長いテキストも試してみましょう。GPT-3.5でテキストをいくつか生成してみます。

データを投入しておきましょう。
supabaseApp.get('index', async c => {
const privateKey = c.env.SUPABASE_PRIVATE_KEY;
const url = c.env.SUPABASE_URL;
const client = createClient(url, privateKey);
const vectorStore = await SupabaseVectorStore.fromTexts(
[
"Supabaseは、オープンソースのデータベースプラットフォームで、リアルタイムでデータベースを管理し、APIを提供し、アプリケーションの開発を簡素化します。",
"Amazon Web Services(AWS)は、クラウドコンピューティングプロバイダーで、仮想サーバー、ストレージ、データベース、AIなどのサービスを提供し、スケーラビリティと柔軟性を備えた企業向けクラウドソリューションを提供します。",
"Cloudflareは、ウェブセキュリティ、コンテンツデリバリ、DNS、DDoS防御などのクラウドサービスを提供し、ウェブアプリケーションの高速化とセキュリティ向上を支援します"
],
[{ id: 12 }, { id: 11 }, { id: 13 }],
new OpenAIEmbeddings({
openAIApiKey: c.env.OPENAI_API_KEY
}),
{
client,
tableName: "documents",
queryName: "match_documents",
}
);
return c.text('ok');
})
あとはgetRelevantDocumentsの検索キーワードを変えるだけです。
const results = await retriever.getRelevantDocuments("データベース");関係性の高いデータが取得できました。
[
{
"pageContent": "Supabaseは、オープンソースのデータベースプラットフォームで、リアルタイムでデータベースを管理し、APIを提供し、アプリケーションの開発を簡素化します。",
"metadata": {
"id": 12
}
},
{
"pageContent": "Amazon Web Services(AWS)は、クラウドコンピューティングプロバイダーで、仮想サーバー、ストレージ、データベース、AIなどのサービスを提供し、スケーラビリティと柔軟性を備えた企業向けクラウドソリューションを提供します。",
"metadata": {
"id": 11
}
},
{
"pageContent": "Cloudflareは、ウェブセキュリティ、コンテンツデリバリ、DNS、DDoS防御などのクラウドサービスを提供し、ウェブアプリケーションの高速化とセキュリティ向上を支援します",
"metadata": {
"id": 13
}
}
]感想
全データをEmbeddingしたからか、あまり全文検索側の恩恵を得られなかったような印象はあります。これは想像ですが、Embeddingしたベクトルデータがないレコードをフォローするために全文検索ができるということかもしれません。
参考
https://js.langchain.com/docs/integrations/retrievers/supabase-hybrid